
In vielen Kundenprojekten liegen die benötigten Daten nicht sauber in einer Datenbank oder hinter einer API, sondern sind auf verschiedenen Webseiten, in Online-Katalogen usw. verteilt. Wenn diese Informationen regelmäßig aktualisiert werden und du sie automatisiert, aktuell und skalierbar verfügbar machen willst, sind Web Crawling (systematisches Durchlaufen von Seiten) und Web Scraping (gezieltes Extrahieren von Daten) oft der pragmatischste Weg. Genau darum geht es in diesem Python Tutorial für Web Crawling und Scraping.
Ein einfaches Skript reicht dann schnell nicht mehr aus, da einige typische Herausforderungen zu bewältigen sind, wie zum Beispiel:
- Skalierbarkeit und Concurrency
- Automatisierung
- Queue-Management inklusive Duplication-Check
- Sessions, Retries und Timeouts
- Zuverlässigkeit auch bei Anti-Bot-Mechanismen
Hier kommen Crawling-/Scraping-Frameworks ins Spiel, die viele dieser Aufgaben übernehmen, sodass man sich stärker auf die eigentliche Datenextraktion und andere Punkte wie Datenqualität konzentrieren kann.
Eines dieser Frameworks, das wir in letzter Zeit gerne in Projekten verwendet haben und hier vorstellen möchten, ist Crawlee.
Was ist Crawlee?
Crawlee ist ein Open-Source-Projekt, das von Apify entwickelt wird. Neben der bereits seit Längerem existierenden JavaScript-Version gibt es auch eine Python-Implementierung, die im September 2025 die Beta-Phase verlassen hat.
Crawlee übernimmt die eben genannten Aufgaben und unterstützt:
- HTTP-basiertes Crawling für „klassische“ serverseitig gerenderte Seiten (schnell, ressourcenschonend)
- Browser-basiertes Crawling für „moderne“ clientseitig gerenderte Seiten
- Adaptives Crawling, das pro Seite zwischen HTTP- und Browser-basiertem Crawling entscheiden kann
- Eine einheitliche Struktur über die Crawling-Typen hinweg (Umstieg ohne komplettes Refactoring)
Durch Crawlees Konfigurationsoptionen kann es mit wenigen Zeilen Code für viele Anwendungsfälle passend konfiguriert werden. Sollte das Problem doch einmal spezieller sein, können auch eigene Crawler implementiert werden, die das Verhalten von Crawlee anpassen oder erweitern.
Praxisbeispiel: Leistungen & Jobs von unserer Webseite scrapen
Für die Implementierung benutzen wir Crawlee 1.6.1 für Python.
Bitte beachte: Die genaue Implementierung ist immer von der Struktur der Ziel-Webseite abhängig (DOM-Struktur, URL-Patterns, Rendering-Verhalten etc.). Sobald sich die Webseite ändert, kann es sein, dass du Anpassungen vornehmen musst, wenn du das Beispiel nachbauen willst.
Für dieses Beispiel setzen wir uns folgendes Ziel:
Wir starten auf der Startseite unserer Webseite, https://www.singular-it.de, und navigieren automatisiert zu den Unterseiten Leistungen und Offene Stellen. Auf beiden Unterseiten extrahieren wir exemplarisch Informationen und geben sie in der Konsole aus.
Wir verwenden den Crawler PlaywrightCrawler von Crawlee, der auf Playwright aufbaut und für Browser-basiertes Crawling geeignet ist. In unserem konkreten Fall würde tatsächlich auch HTTP-basiertes Crawling ausreichen, der Browser-Ansatz hat für uns aber zwei Vorteile:
- Das grundsätzliche Vorgehen ist bei beiden Crawling-Arten gleich. Beim Browser-basierten Crawling sind allerdings noch ein paar zusätzliche Dinge zu beachten. Dazu zählen beispielsweise Wartebedingungen, die wir so kennenlernen können.
- Zur besseren Anschaulichkeit können wir im Browser sehen, welche Seiten aufgerufen werden.
Voraussetzungen und Setup
Die einzige Voraussetzung, um das Beispiel selbst nachzubauen, ist eine Installation des Paket- und Projektmanagers uv.
Dann können wir in einem neuen Ordner mit
uv init
ein neues Projekt anlegen und mit
uv add crawlee[playwright]==1.6.1 uv add tabulate==0.10.0
unsere Dependencies installieren. Um den PlaywrightCrawler verwenden zu können, brauchen wir neben dem Standardpaket von Crawlee noch das Extra playwright. Außerdem verwenden wir noch tabulate, um die Ausgabe der gescrapten Daten in der Konsole zu formatieren.
Vorgehen mit Crawlee
Im Grundprinzip verwaltet Crawlee eine allgemeine Warteschlange (Queue), die nach und nach abgearbeitet wird. Für das Abarbeiten definiert man einen oder mehrere Handler.
Das anschließende Vorgehen:
- Man fügt der Queue explizit eine oder mehrere Start-URLs hinzu.
- Man startet den Crawler. Die Handler arbeiten nun die Seiten in der Queue ab. Dazu können die Handler Daten scrapen und nach weiteren Links suchen, die wiederum zur Queue hinzugefügt werden.
- Der Crawler stoppt erst dann, wenn sich keine Seiten mehr in der Queue befinden oder wenn ein selbst definiertes Stopp-Kriterium erfüllt ist.
Wir teilen unser Beispiel in zwei Dateien auf:
main.pyum den Crawler zu initialisieren und zu startenroutes.pyum die Handler zu definieren
Crawler Setup
Bevor wir den Crawler starten, müssen wir ihn konfigurieren. Wir wählen Einstellungen, die sich gut zur Nachvollziehbarkeit und zum Testen eignen:
- Nur 1 Request gleichzeitig
- Max. 1 Request alle 5 Sekunden
- Sichtbarer Browser
- Max. 3 Requests (damit wir nicht aus Versehen zu viele Seiten scrapen)
Als Erstes programmieren wir die main.py-Datei. Nachdem wir alle benötigten Module mit
import asyncio from crawlee import ConcurrencySettings from crawlee.crawlers import PlaywrightCrawler from routes import router
importiert haben, können wir in der main-Funktion den Crawler mit wenigen Code-Zeilen konfigurieren und den Crawl auf der Hauptseite starten:
async def main() -> None:
crawler = PlaywrightCrawler(
concurrency_settings=ConcurrencySettings(
desired_concurrency=1,
max_concurrency=1,
max_tasks_per_minute=12,
),
headless=False,
max_requests_per_crawl=3,
request_handler=router,
)
await crawler.run(["https://www.singular-it.de/"])Um das Ganze als Skript ausführen zu können, fügen wir noch
if __name__ == "__main__": asyncio.run(main())
am Ende der Datei an.
Damit ist die main.py schon fertig und es fehlt noch die Implementierung der eigentlichen Scraping-Logik, die wir aus routes.py importiert haben.
Webseite untersuchen
Bevor wir diese Logik implementieren, müssen wir die Seiten, die wir scrapen wollen, untersuchen, um herauszufinden, wie wir an die gewünschten Daten herankommen.
Schauen wir uns dazu die Beispielseite https://www.singular-it.de einmal genauer an. Im Browser können wir uns die Struktur der Seite anzeigen lassen. Je nach Browser funktioniert das etwas unterschiedlich. In Chrome-basierten Browsern können wir beispielsweise mit einem Rechtsklick auf ein Element und der Auswahl von „Inspect“ bzw. „Untersuchen“ das ausgewählte Element in der Struktur der Seite finden. Für die beiden Unterseiten, zu denen wir navigieren wollen, sieht das dann so aus:
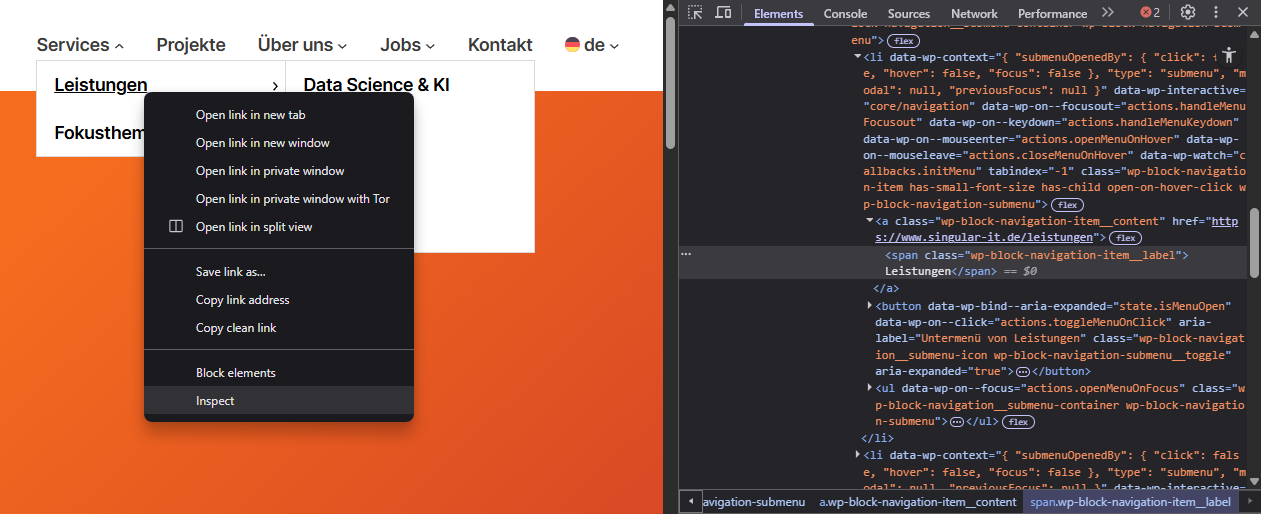
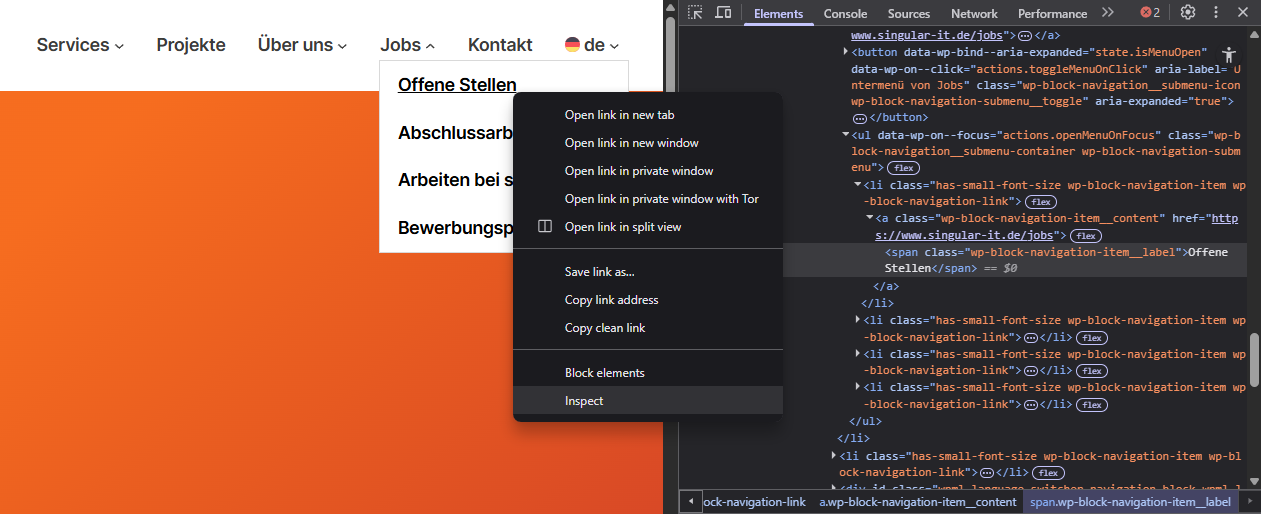
Hier können wir auf der rechten Seite sehen, dass beide Links in a-Elementen mit Klasse wp-block-navigation-item__content zu finden sind. Damit können wir uns jetzt die Handler definieren.
Handler Setup
In der routes.py-Datei importieren wir
from crawlee import RequestOptions, RequestTransformAction from crawlee.crawlers import PlaywrightCrawlingContext from crawlee.router import Router from tabulate import tabulate
und definieren zunächst den Router, den wir in main.py importiert haben:
router = Router[PlaywrightCrawlingContext]()
Der Router erlaubt es, Handler zu registrieren. Wenn wir Requests mit einem Label versehen, kann der Router die Requests dann abhängig vom Label an die Handler verteilen.
Standard-Handler
Als ersten Handler registrieren wir einen Standard-Handler, der Requests ohne Label verarbeitet. In unserem Fall wird das nur die Start-URL sein, weil wir die anderen Requests mit Labels versehen werden:
@router.default_handler
async def default_handler(context: PlaywrightCrawlingContext) -> None:
context.log.info(f"Processing {context.request.url} ...")
await context.page.wait_for_selector("a.wp-block-navigation-item__content")
await context.enqueue_links(
selector="a.wp-block-navigation-item__content",
transform_request_function=transform_request,
)Dem Handler wird als Argument ein Context-Objekt übergeben, das alles enthält, was wir nun zur Verarbeitung benutzen werden.
Als Erstes können wir mit dem Logger ausgeben, welche Seite gerade verarbeitet wird.
Als Nächstes fügen wir eine Wartebedingung hinzu. Das ist wichtig beim Browser-basierten Crawling, da Elemente oft erst nachgeladen werden. Wie genau diese Wartebedingung lauten muss, kann man pauschal nicht sagen. Hier ist Ausprobieren angesagt. Wir warten hier exemplarisch einfach auf die Elemente, die wir beim Untersuchen der Start-URL identifiziert haben.
Wenn wir Elemente selektieren wollen, etwa wie gerade bei der Wartebedingung, können wir das mithilfe sogenannter CSS-Selektoren tun. Mit ihnen kann man sehr genau angeben, welche Elemente selektiert werden sollen. Wir werden auf deren Syntax nicht genauer eingehen, mit
a.wp-block-navigation-item__contentwählen wir aber genau solche Elemente aus, die wir beim Untersuchen der Startseite identifiziert haben:a-Elemente mit Klassewp-block-navigation-item__content.
Zuletzt können wir mit der Methode enqueue_links() weitere Requests zur Queue hinzufügen. Auch hier können wir unseren CSS-Selektor angeben, um uns auf URLs aus bestimmten Elementen zu beschränken. Mit diesem Selektor alleine ist die Filterung aber noch zu grob, denn wir würden auch noch Requests für andere Unterseiten zur Queue hinzufügen. Daher definieren wir noch eine Funktion transform_request(), um die Filterung zu verfeinern:
def transform_request(
request_options: RequestOptions,
) -> RequestOptions | RequestTransformAction:
if request_options["url"].endswith("/leistungen"):
request_options["label"] = "services"
elif request_options["url"].endswith("/jobs"):
request_options["label"] = "jobs"
else:
return "skip"
return request_optionsIn dieser Funktion können wir Requests unverändert weitergeben oder überspringen, indem wir "unchanged" oder "skip" zurückgeben, und auch verändern, indem wir request_options modifizieren und zurückgeben.
Wir identifizieren die beiden Requests, die uns interessieren, anhand der Endungen ihrer URLs und fügen ihnen noch unterschiedliche Labels hinzu, damit wir sie separat verarbeiten können. Andere Requests überspringen wir.
Für diese Labels müssen wir nun noch die Handler registrieren.
Label-Handler
Fangen wir mit dem Handler für die Leistungen an. Wir wollen die von uns angebotenen Leistungen scrapen. Um die relevanten Elemente zu finden, untersuchen wir wieder die entsprechende Seite und finden heraus, dass die Leistungen genau in den h2-Elementen mit Klasse wp-block-heading stehen:
@router.handler("services")
async def services_handler(context: PlaywrightCrawlingContext) -> None:
context.log.info(f"Processing {context.request.url} ...")
await context.page.wait_for_selector("h2.wp-block-heading")
services = await context.page.locator("h2.wp-block-heading").all_text_contents()
context.log.info(f"Scraped services: {', '.join(services)}")Wir beginnen ähnlich wie bei dem Standard-Handler, extrahieren dann die Textinhalte der gefundenen Elemente und geben sie mit dem Logger aus.
Bei dem Handler für unsere Stellenangebote können wir analog vorgehen. Dabei verwenden wir zusätzlich noch tabulate für die Formatierung der Ausgabe:
@router.handler("jobs")
async def jobs_handler(context: PlaywrightCrawlingContext) -> None:
context.log.info(f"Processing {context.request.url} ...")
await context.page.wait_for_selector("div.job-offer")
jobs = []
for job in await context.page.locator(
"div.job-offer",
).all():
position = await job.locator("a").first.text_content()
link = await job.locator("a").first.get_attribute("href")
details = await job.locator("p").first.text_content()
jobs.append(
{
"position": position,
"details": details,
"link": link,
}
)
context.log.info(
"Scraped Jobs offers:\n"
+ tabulate(
tabular_data=jobs, headers="keys", tablefmt="simple_grid", maxcolwidths=40
)
)Damit ist auch routes.py fertig.
Insgesamt sehen unsere beiden Dateien dann so aus:
main.py
import asyncio
from crawlee import ConcurrencySettings
from crawlee.crawlers import PlaywrightCrawler
from routes import router
async def main() -> None:
crawler = PlaywrightCrawler(
concurrency_settings=ConcurrencySettings(
desired_concurrency=1,
max_concurrency=1,
max_tasks_per_minute=12,
),
headless=False,
max_requests_per_crawl=3,
request_handler=router,
)
await crawler.run(["https://www.singular-it.de/"])
if __name__ == "__main__":
asyncio.run(main())routes.py
from crawlee import RequestOptions, RequestTransformAction
from crawlee.crawlers import PlaywrightCrawlingContext
from crawlee.router import Router
from tabulate import tabulate
router = Router[PlaywrightCrawlingContext]()
def transform_request(
request_options: RequestOptions,
) -> RequestOptions | RequestTransformAction:
if request_options["url"].endswith("/leistungen"):
request_options["label"] = "services"
elif request_options["url"].endswith("/jobs"):
request_options["label"] = "jobs"
else:
return "skip"
return request_options
@router.default_handler
async def default_handler(context: PlaywrightCrawlingContext) -> None:
context.log.info(f"Processing {context.request.url} ...")
await context.page.wait_for_selector("a.wp-block-navigation-item__content")
await context.enqueue_links(
selector="a.wp-block-navigation-item__content",
transform_request_function=transform_request,
)
@router.handler("services")
async def services_handler(context: PlaywrightCrawlingContext) -> None:
context.log.info(f"Processing {context.request.url} ...")
await context.page.wait_for_selector("h2.wp-block-heading")
services = await context.page.locator("h2.wp-block-heading").all_text_contents()
context.log.info(f"Scraped services: {', '.join(services)}")
@router.handler("jobs")
async def jobs_handler(context: PlaywrightCrawlingContext) -> None:
context.log.info(f"Processing {context.request.url} ...")
await context.page.wait_for_selector("div.job-offer")
jobs = []
for job in await context.page.locator(
"div.job-offer",
).all():
position = await job.locator("a").first.text_content()
link = await job.locator("a").first.get_attribute("href")
details = await job.locator("p").first.text_content()
jobs.append(
{
"position": position,
"details": details,
"link": link,
}
)
context.log.info(
"Scraped job offers:\n"
+ tabulate(
tabular_data=jobs, headers="keys", tablefmt="simple_grid", maxcolwidths=40
)
)Crawl starten
Wenn wir jetzt den Crawl mit
uv run main.py
starten, öffnet sich ein Browser und wir können den Crawl verfolgen.
Zugegebenermaßen passiert hier nicht sehr viel, aber sobald die Wartebedingungen komplexer werden und auch mit Elementen interagiert werden muss, zum Beispiel durch Buttonklicks, kann es fürs Debugging sehr hilfreich sein, den Browser zu sehen.
Außerdem sieht man in der Konsole die Ausgaben des Crawlers. Neben den Logging-Ausgaben, die wir selbst implementiert haben, gibt auch Crawlee selbst standardmäßig einige Informationen zum aktuellen Zustand und Fortschritt während des Crawls aus. Gerade bei größeren Crawls sollte man sich Gedanken machen, ob und wie man diese Ausgaben sinnvoll speichert.
Rechtliche Hinweise und Richtlinien
Neben den technischen Herausforderungen beim Crawling gibt es auch rechtliche Vorgaben, an die man sich halten muss, und Richtlinien, die man befolgen sollte. Wir werden dieses Thema hier nur kurz anreißen und beschränken uns daher auf einige der wichtigsten Punkte:
- Gesetzliche Vorgaben: Beim Web Crawling und Scraping müssen die rechtlichen Bestimmungen zum Urheberrecht beachtet werden (zum Beispiel § 44b UrhG).
robots.txtbeachten: Webseiten stellen oft einerobots.txt-Datei bereit, die vorgibt, welche Teile der Seite von Crawlern und Bots abgerufen werden dürfen und welche nicht.
Anfragen begrenzen: Um keine Server zu überlasten, sollten beim Crawling die Anfragen pro Domain beschränkt werden.
Andere Frameworks
Natürlich gibt es neben Crawlee noch weitere Crawling-/Scraping-Frameworks mit unterschiedlichen Stärken und Schwächen. Zwei der bekanntesten sind Scrapy und Crawl4AI.
Im Vergleich zu Scrapy weist Crawlee die modernere Architektur auf und unterstützt viele Features nativ, für die in Scrapy Add-ons benötigt werden. Insbesondere punktet Crawlee durch Einsteigerfreundlichkeit, während Scrapy eine recht steile Lernkurve hat. Auf der anderen Seite ist Scrapy eines der etabliertesten Frameworks mit einer sehr großen Community, sodass auch für viele Spezialfälle ein Add-on zu finden ist.
Crawl4AI ist wie Crawlee ein vergleichsweise junges Projekt, das, wie der Name schon vermuten lässt, stark auf AI ausgerichtet ist. Während Crawlee eher beim Skalieren seine Stärken hat, kann sich ein Blick auf Crawl4AI lohnen, falls die extrahierten Daten direkt zur Weiterverarbeitung mit LLMs aufbereitet werden sollen.
Next Steps
Natürlich haben wir mit diesem Python Tutorial für Web Crawling und Scraping nur einen kleinen Einblick in dieses Thema und zu Crawlee gegeben. Auf der offiziellen Webseite kann man nicht nur mehr über Crawlee lernen, sondern die Tutorials dort vermitteln auch Wissen und Skills, die generell beim Crawling und Scraping hilfreich sind, egal für welches Framework man sich letztendlich entscheidet.